Graphs - Theory
Summary of GNN lectures
How Expressive are GNNs?#
- Recap a GNN Layer
Expressive Power of GNNs#
We use node same/different colors to represent nodes with same/different features.
Local Neighborhood Structures#
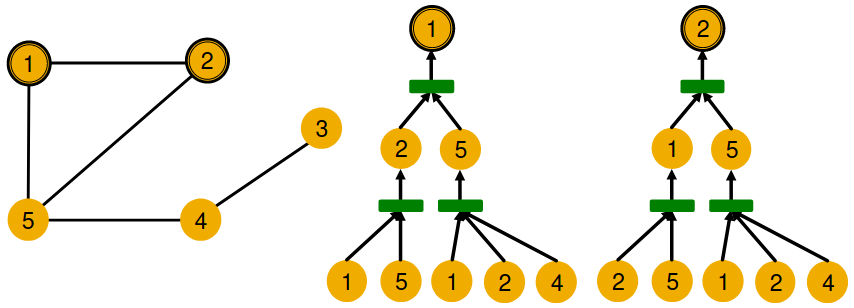
They are symmetric within the graph.
- Node 1 has neighbors of degrees 2 and 3.
- Node 2 has neighbors of degrees 2 and 3.
And even if we go a step deeper to 2nd hop neighbors, both nodes have the same degrees (Node 4 of degree 2)
But GNN only sees node features (not IDs):
- A GNN will generate the same embedding for nodes 1 and 2 because:
- Computational graphs are the same.
- Node features (colors) are identical.
In general, different local neighborhoods define different computational graphs
GNN’s node embeddings capture rooted subtree structures.
Expressive GNNs should map subtrees to the node embeddings injectively.
Key observation: Subtrees of the same depth can be recursively characterized from the leaf nodes to the root nodes.
If each step of GNN’s aggregation can fully retain the neighboring information, the generated node embeddings can distinguish different rooted subtrees.
In other words, most expressive GNN would use an injective neighbor aggregation function at each step.
Computational graph = Rooted subtree
Key observation: Expressive power of GNNs can be characterized by that of neighbor aggregation functions they use.
- A more expressive aggregation function leads to a more expressive a GNN.
Neighbor Aggregation#
GCN (mean-pool), Kipf and Welling, ICLR 2017
Element-wise mean pooling + Linear + ReLU non-linearity
- GCN’s aggregation function cannot distinguish different multi-sets with the same color proportion. - Theorem [Xu et al. ICLR 2019] → not injective
GraphSAGE (max-pool), Hamilton et al., NeurIPS 2017
MLP + element-wise max-pooling
- GraphSAGE’s aggregation function cannot distinguish different multi-sets with the same set of distinct colors. - Theorem [Xu et al. ICLR 2019] → not injective
Graph Isomorphism Network (GIN)#
Proof Intuition#
and are some non-linear functions.
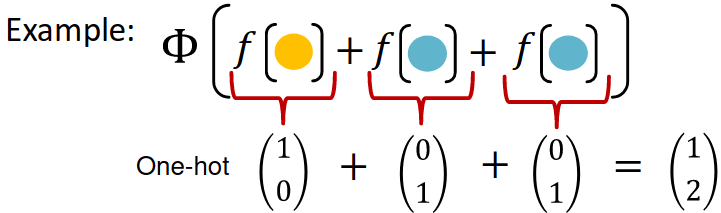
produces one-hot encodings of colors. Summation of the one-hot encodings retains all the information about the input multi-set.
Universal Approximation Theorem [Hornik et al., 1989]
- 1-hidden-layer MLP with sufficiently-large hidden dimensionality and appropriate non-linearity (including ReLU and sigmoid) can approximate any continuous function to an arbitrary accuracy.
the full model of GIN by relating it to WL graph kernel (traditional way of obtaining graph-level features).
Any injective function over the tuple,
can be modeled as
is a learnable scalar.
- previous Graphs - Aug. and Training
- next Graphs - KG Embedding