Graphs - Reasoning
Reasoning over KG
This post based on Lecture 11 of CS224W
Reasoning over Knowledge Graphs#
Goal:
- How to perform multi-hop reasoning over KGs?
Reasoning over Knowledge Graphs
- Answering multi-hop queries
- Path Queries
- Conjunctive Queries
- Query2Box
Predictive Queries on KG#
Can we do multi-hop reasoning, i.e., answer complex queries on an incomplete, massive KG?

KG completion: Is link in the KG?
One-hop Queries#
One-hop query: Is an answer to query ?
- For example:
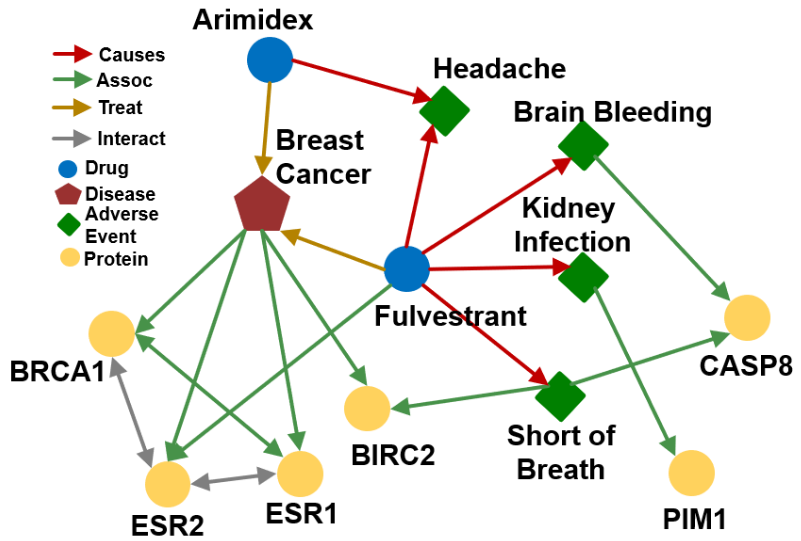
- Q: What side effects are caused by drug Fulvestrant?
- A: [Headache, Brain Bleeding, Kidney Infection, Short of Breath]
Path Queries#
Generalize one-hop queries to path queries by adding more relations on the path.
An -hop path query can be represented by
- is an “anchor” entity,
- Let answers to in graph be denoted by .
Query Plan of :
Query plan of path queries is a chain.
- For example:
- Q: “What proteins are associated with adverse events caused by Fulvestrant?”
- A: [BIRC2, CASP8, PIM1]
is :Fulvestrant
is (:Causes, :Assoc)
Query: (:Fulvestrant, (:Causes, :Assoc))
- Answering queries seems easy: Just traverse the graph.
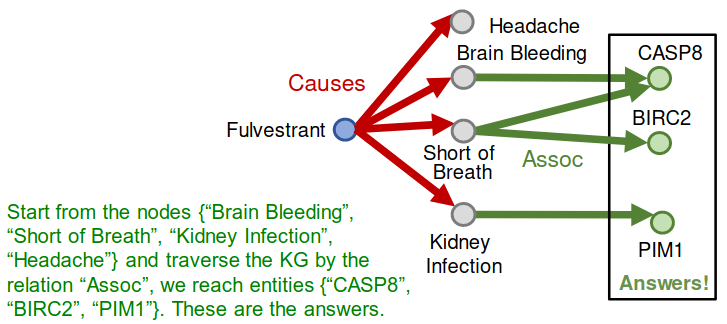
- But KGs are incomplete and unknown:
- For example, we lack all the biomedical knowledge
- Enumerating all the facts takes non-trivial time and cost, we cannot hope that KGs will ever be fully complete
- Due to KG incompleteness, one is not able to identify all the answer entities
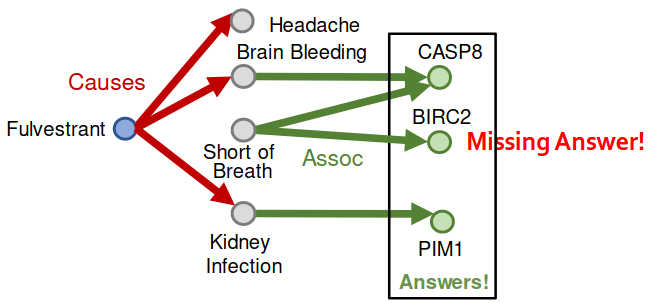
위의 그래프와 비교하면 Fulvestrant와 Short of Breath의
Causesrelation이 없다. 이로 인해 BIRC2라는 단백질에 대하여 정상적인 relation을 찾기 어렵다.
Can we first do KG completion and then traverse the completed (probabilistic) KG?
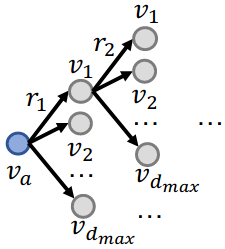
- No! The “completed” KG is a dense graph!
- Most triples (edge on KG) will have some non-zero probability.
- Time complexity of traversing a dense KG is exponential as a function of the path length :
Answering Predictive Queries on Knowledge Graphs#
Predictive Queries#
We need a way to answer path-based queries over an incomplete knowledge graph.
We want our approach to implicitly impute and account for the incomplete KG.
- Want to be able to answer arbitrary queries while implicitly imputing for the missing information
- Generalization of the link prediction task
Given entity embeddings, how do we answer an arbitrary query?
- Path queries: Using a generalization of TransE
- Conjunctive queries: Using Query2Box
- And-Or Queries: Using Query2Box and query rewriting
(We will assume entity embeddings and relation embeddings are given)
How do we train the embeddings?
- The process of determining entity and relation embeddings which allow us to embed a query.
General Idea#
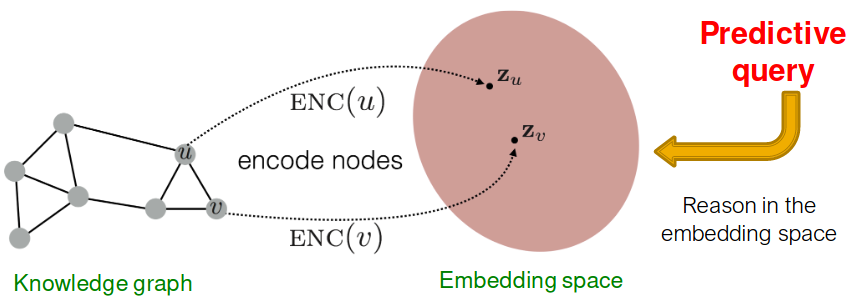
Map queries into embedding space. Learn to reason in that space
- Embed query into a single point in the Euclidean space: answer nodes are close to the query.
- Query2Box: Embed query into a hyper-rectangle (box) in the Euclidean space: answer nodes are enclosed in the box.
Guu, et al., Traversing knowledge graphs in vector space, EMNLP 2015.
Key idea: Embed queries!
- Generalize TransE to multi-hop reasoning.
Recap: TransE: Translate to using with score function .
Another way to interpret this is that:
Query embedding:
Goal: query embedding is close to the answer embedding
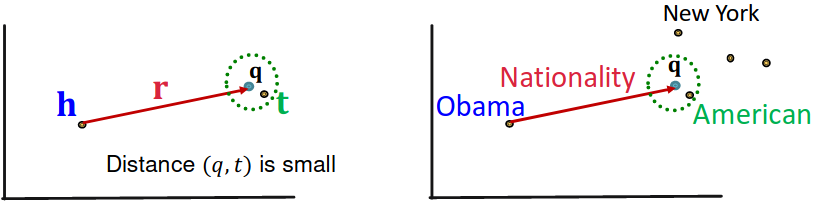
Given a path query ,
The embedding process only involves vector addition, independent of # entities in the KG!
- Q: “What proteins are associated with adverse events caused by Fulvestrant?”
- A: [BIRC2, CASP8, PIM1]
Query: (:Fulvestrant, (:Causes, :Assoc))
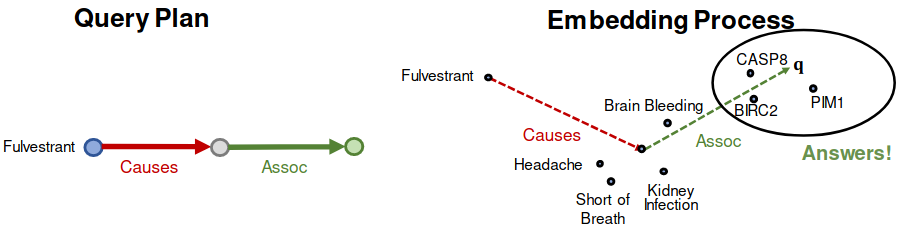
TransE는 path query 처리가 가능하다. compositional relations이 가능하기 때문이다.
TransR / DistMult / ComplEx는 path query 처리에 어려움이 있다.
TransR 역시 compositional relations이 가능하지만, relation들 간의 직접적인 연관아 아니라 projection matrix를 거쳐야 해서 path query 처리가 힘들어 사용하지 않는다.
Conjunctive Queries#
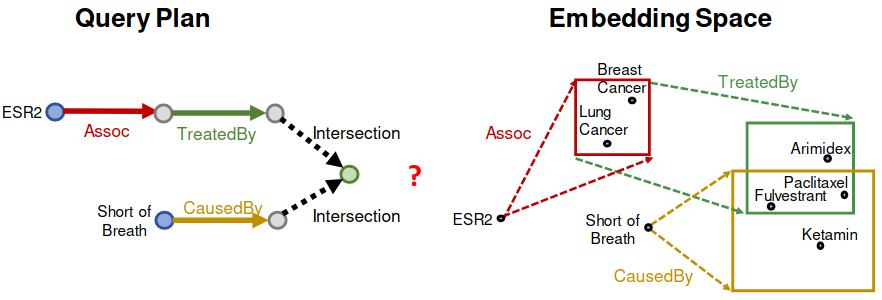
Q: “What are drugs that cause Short of Breath and treat diseases associated with protein ESR2?”
A: [”Fulvestrant”]
((: ESR2, (: Assoc, : TreatedBy)), (: Short of Breath, (: CausedBy))
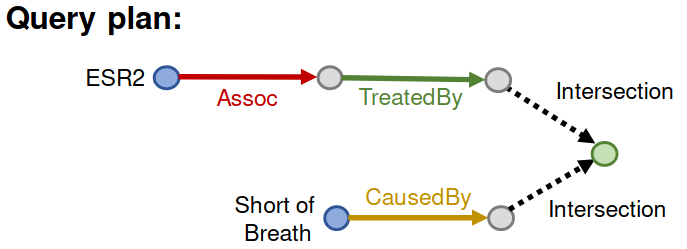
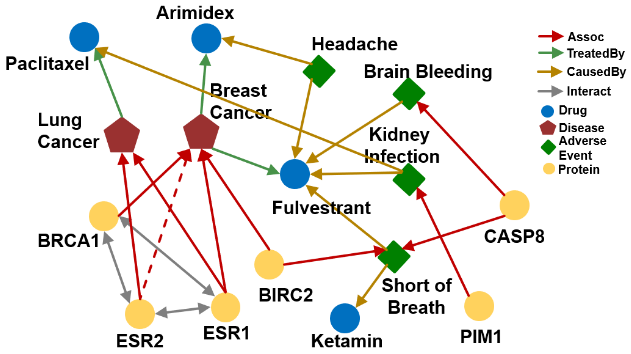
Following the graph, ESR2’s associate relation is missing. Thus, we can’t find Fulvestrant.
How can we use embeddings to implicitly impute the missing (ESR2, Assoc, Breast Cancer)?
Intuition: ESR2 interacts with both BRCA1 and ESR. Both proteins are associated with breast cancer.
How can we answer more complex queries with logical conjunction operation?
- Each intermediate node represents a set of entities, how do we represent it?
- How do we define the intersection operation in the latent space?
Query2Box#
Ren et al., Query2box: Reasoning over Knowledge Graphs in Vector Space Using Box Embeddings, ICLR 2020
Embed queries with hyper-rectangles (boxes)
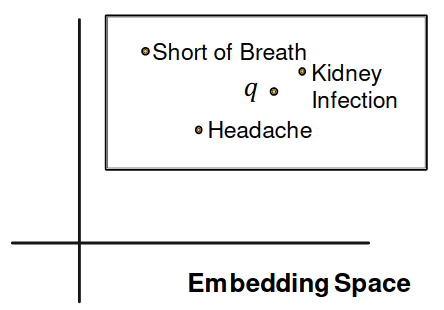
Boxes are a powerful abstraction, as we can project the center and control the offset to model the set of entities enclosed in the box
: out degree
: # entities
: # relations
Things to figure out:
- Entity embeddings (# params: ):
- Entities are seen as zero-volume boxes
- Relation embeddings (# params: ):
- Each relation takes a box and produces a new box
- Intersection operator :
- New operator, inputs are boxes and output is a box
- Intuitively models intersection of boxes
Q: “What are drugs that cause Short of Breath and treat diseases associated with protein ESR2?”
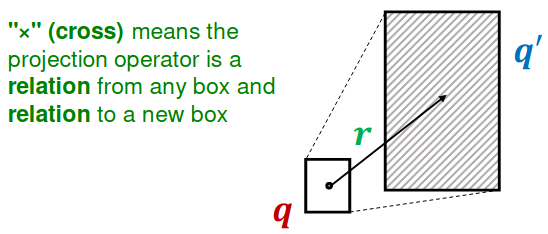
Projection Operator #
Intuition:
- Take the current box as input and use the relation embedding to project and expand the box!
Geometric Intersection Operator #
Take multiple boxes as input and produce the intersection box
Intuition:
- The center of the new box should be “close” to the centers of the input boxes
- The offset (box size) should shrink (since the size of the intersected set is smaller than the size of all the input set)
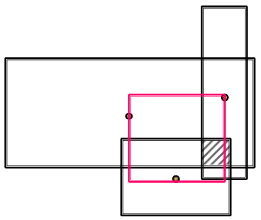
: trainable weights are calculated by a neural network ; represents a “self-attention” score for the center of each input .
Intuition: The center should be in the red region!
Implementation: The center is a weighted sum of the input box centers
: guarantees shrinking
: a neural network that extracts the representation of the input boxes to increase expressiveness
: Sigmoid function (0, 1);
Intuition: The offset should be smaller than the offset of the input box
Implementation: We first take minimum of the offset of the input box, and then we make the model more expressive by introducing a new function to extract the representation of the input boxes with a sigmoid function to guarantee shrinking.
Entity-to-Box Distance#
How do we define the score function (negative distance)?
( captures inverse distance of a node as answer to )
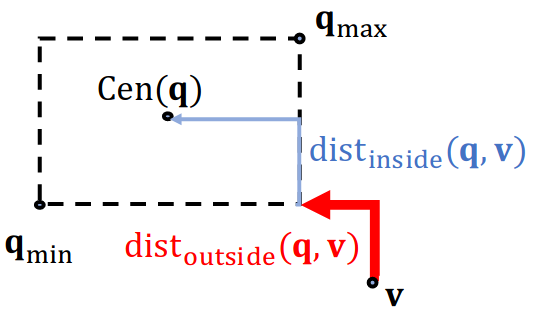
Given a query box and entity embedding (box) ,
where .
: a query box
: an entity vector
: the distance
Intuition: if the point is enclosed in the box, the distance should be downweighted.
- Examples:
is 0.5.- 1 + 0.5(3) = 2.5; outside the box = -2.5
- 0 + 0.5(3) = 1.5; at the line of the box = -1.5
- 0 + 0.5(1) = 0.5; in the box = -0.5
Union Operation#
Can we embed complex queries with union?
(e.g.: “What drug can treat breast cancer or lung cancer?”)
Conjunctive queries + disjunction is called Existential Positive First-Order (EPFO) queries.
We’ll refer to them as AND-OR queries.
Can we also design a disjunction operator and embed AND-OR queries in low-dimensional vector space?
- No! Intuition: Allowing union over arbitrary queries requires high-dimensional embeddings!
Given 3 queries , , , with answer sets:
- , ,
- If we allow union operation, can we embed them in a two-dimensional plane?
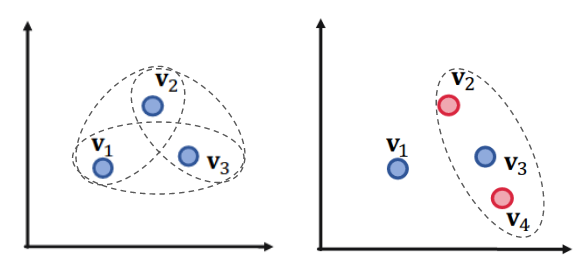
If given 4 queries , , , with answer sets:
- We cannot design a box embedding for , that only and are in the box but is in the box.
Conclusion: Given any conjunctive queries with non-overlapping answers, we need dimensionality of to handle all OR queries.
- For real-world KG, such as FB15k, we find , where .
- Remember, this is for arbitrary OR queries.
Can’t we still handle them?
Key idea: take all unions out and only do union at the last step!
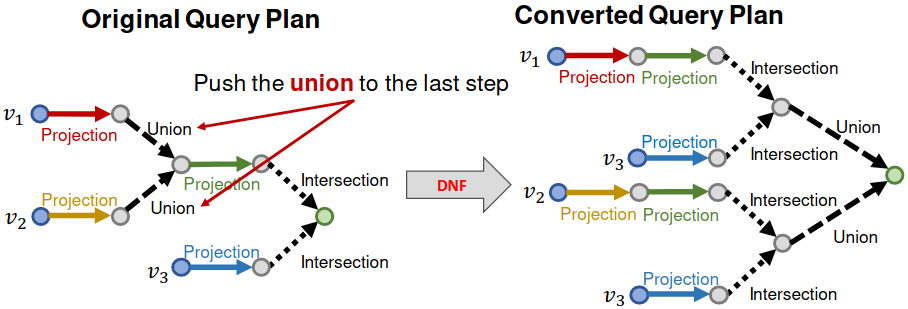
Disjunctive Normal Form#
Any AND-OR query can be transformed into equivalent DNF, i.e., disjunction of conjunctive queries.
Given any AND-OR query ,
. where is a conjunctive query.
Now we can first embed each and then “aggregate” at the last step!
Distance between entity embedding and a DNF () is defined as:
Intuition:
- As long as is the answer to one conjunctive query , then should be the answer to
- As long as is close to one conjunctive query ,then should be close to in the embedding space
The process of embedding any AND-OR query :
- Transform to equivalent DNF
- Embed to
- Calculate the (box) distance
- Take the minimum of all distance
- The final score
How to Train Query2Box#
Overview and Intuition (similar to KG completion):
Given a query embedding , maximize the score for answers and minimize the score for negative answers
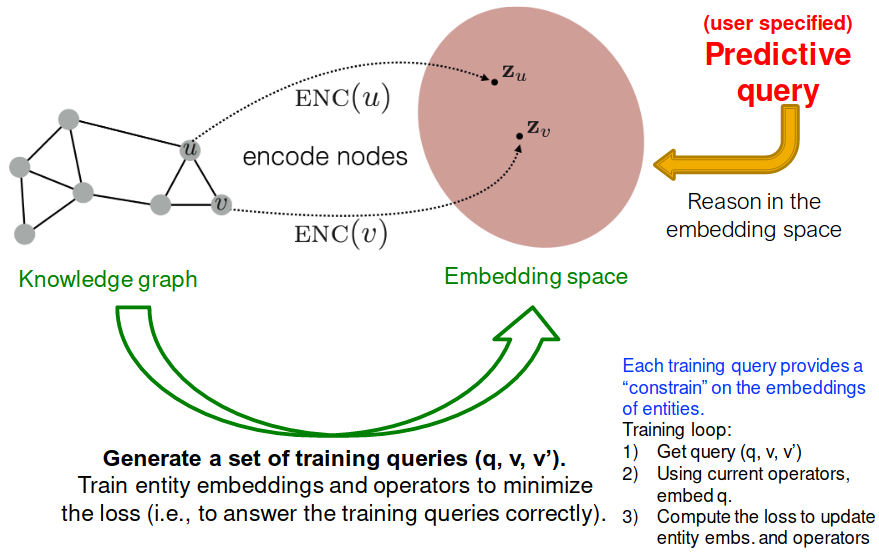
Training:
- Sample a query from the training graph , answer , and non-answer
- Embed the query .
- Use current operators, to compute query embedding.
- Calculate the score and .
- Optimize embeddings and operators to minimize the loss (maximize while minimize :
- previous Graphs - KG Embedding
- next RL - Overview