Graphs - Neural Networks
Summary of GNN lectures
Graph Neural Networks#
Limitations of Shallow embedding methods#
Embedding matrix , It’s shape. (dim. of embds, # nodes)
- parameters are needed:
- No sharing of parameters between nodes
- Every node has its own unique embedding
- Inherently “transductive”:
- Cannot generate embeddings for nodes that are not seen during training
- Do not incorporate node features:
- Nodes in many graphs have features that we can and should leverage
Graph#
: multiple layers of non-linear transformations based on graph structure
Tasks we will be able to solve:
- Node classification: Predict the type of a given node
- Link prediction: Predict whether two nodes are linked
- Community detection: Identify densely linked clusters of nodes
- Network similarity: How similar are two (sub)networks
Graph networks are more complex than images or text. (Arbitray size, complex topological structure)
Fundamental Func.
Adjacency matrix를 linear layer에 그대로 넣게 되면, linear layer의 weight들은 node order에 민감하여, 순서가 변경되면 매우 다른 값을 가지게 된다. 또한 paramters를 가지게 되고, 고정된 feature dim으로 다른 크기의 graph를 사용할 수 없다.
Graph does not have a canonical order of the nodes!
Graph is permutation invariant
is a matrix of node features.
Permutation Invariant#
Then, if for any order plan and , we formally say is a permutation invariant function.
- Definition: For any graph function , is permutation-invariant if for any permutation .
- Permute the input, the output stays the same. (map a graph to a vector)
- e.g. : sum, average, pooling
Permutation Equivariance#
If the output vector of a node at the same position in the graph remains unchanged for any order plan, we say is permutation equivariant.
- Definition: For any node function , is permutation-equivariant if for any permutation .
- Permute the input, output also permutes accordingly. (map a graph to a matrix)
- e.g. : RNN, Self-attention
Examples:
- : Permutation-invariant
- : Permutation-equivariant
- : Permutation-equivariant
Graph Convolutional Networks#
Idea: Node’s neighborhood defines a computation graph
cs224w - lecture 4. slide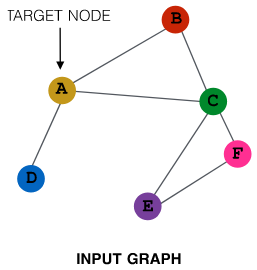
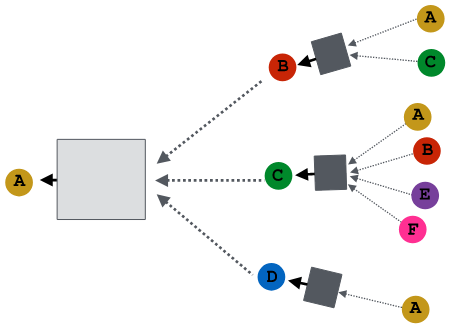
Intuition: Nodes aggregate information from their neighbors using neural networks
Model can be of arbitrary depth.
Neighborhood Aggregation#
Neighborhood aggregation: Key distinctions are in how different approaches aggregate information across the layers
Basic approach.
: Initial 0th layer embeddings are equal to node features.
: Non-linearity activation function.
: Average of neighbor’s previous layer embeddings.
: Embedding of at layer
: Embedding after K layers of neighborhood aggregation
: weight matrix for neighborhood aggregation
: weight matrix for transforming hidden vector of self
GCN: Invariance and Equivariance#
Given a node, the GCN that computes its embedding is permutation invariant.
Average of neighbor’s previous layer embeddings - Permutation invariant.
(Average 때문 순서 상관 없다)
Considering all nodes in a graph, GCN computation is permutation equivariant.
cs224w - lecture 4. slide
- Let , then
- Diagonal matrix
- Therefore, is .
How to Train a GNN#
Supervised setting#
Node label available
: Encoder output
: Node class label
: Classification weights
Unsupervised setting#
No node label available
Use the graph structure as the supervision!
“Similar” nodes have similar embeddings
is the decoder such as inner product.
Model Process#
- Define a neighborhood aggregation
- Define a loss function on the embeddings
- Train on a set of nodes, i.e., a batch of compute graphs
- Generate embeddings for nodes as needed (Only compute the relevant nodes in the batch.)
Inductive Capability: New Nodes and New Graphs#
The same aggregation parameters are shared for all nodes:
- The number of model parameters is sublinear in and we can generalize to unseen nodes!
Inductive node embedding –> Generalize to entirely unseen graphs
A General Perspective on GNN#
A General GNN Framework#
cs224w - lecture 5. slide
- Message
- Aggregation
- Layer connectivity
- Graph augmentation
Idea: Raw input graph Computational graph- Graph feature augmentation
- Graph structure augmentation
- Learning objective
A Single Layer of a GNN#
Idea of a GNN Layer: Compress a set of vectors into a single vector
Message#
Message function: Each node will create a message, which will be sent to other nodes later.
If message function() is a linear layer,
Aggregation#
Intuition: Each node will aggregate the messages from node ’s neighbors
Possible aggregation functions,
Issue: Information from node itself could get lost
- message 내에 포함된 정보는 자신을 제외한 이웃 노드들의 정보만 가지고 있기 때문이다.
Solution:
- Compute message from node itself.
Finally,
- Message:
- Aggregation:
Classical GNN Layers#
Recap: a single GNN layer
Graph Convolutional Networks (GCN)#
GraphSAGE#
- Message is computed within the
- Two-stage aggregation
Neighbor aggregation methods#
- Mean: Take a weighted average of neighbors
- Pool: Transform neighbor vectors and apply symmetric vector function or
- LSTM: Apply LSTM to reshuffled of neighbors
Normalization#
where
Graph Attention Networks#
In GCN and GraphSAGE:
- is weighting factor (importance) of node ’s message to node .
- is defined explicitly based on the structural properties of the graph (node degree).
- All neighbors are equally important to node .
Goal: Specify arbitrary importance to different neighbors of each node in the graph
Idea: Compute embedding of each node in the graph following an attention strategy:
- Nodes attend over their neighborhoods’ message
- Implicitly specifying different weights to different nodes in a neighborhood
Attention Mechanism#
Let be computed as a byproduct of an attention mechanism :
Let compute attention coefficients across pairs of nodes , based on their messages:
Normalize with softmax
Weighted sum based on the final attention weight
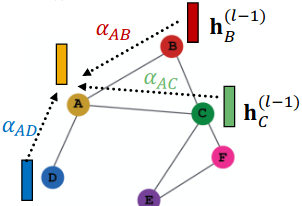 cs224w - lecture 5. slide
cs224w - lecture 5. slide
What is the form of attention mechanism ?
The approach is agnostic to the choice of
- Simple example
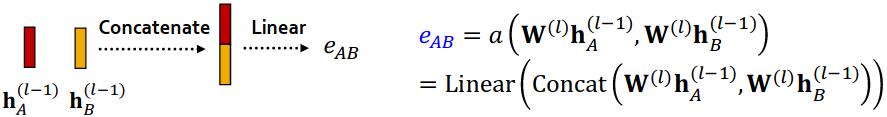 cs224w - lecture 5. slide
cs224w - lecture 5. slide
Multi-head attention#
Stabilizes the learning process of attention mechanism
(하나의 head로만은 bias 되기 쉽다.)
Key benefit: Allows for (implicitly) specifying different importance values () to different neighbors
- Computationally efficient:
- Computation of attentional coefficients can be parallelized across all edges of the graph
- Aggregation may be parallelized across all nodes
- Storage efficient:
- Sparse matrix operations do not require more than entries to be stored
- Fixed number of parameters, irrespective of graph size
- Localized:
- Only attends over local network neighborhoods
- Inductive capability:
- It is a shared edge-wise mechanism
- It does not depend on the global graph structure
Batch Normalization#
: Trainable Parameters
Stacking Layers of a GNN#
How to construct a Graph Neural Network?
- The standard way: Stack GNN layers sequentially
The Issue of stacking many GNN layers
GNN suffers from the over-smoothing problem
The over-smoothing problem: all the node embeddings converge to the same value
- This is bad because we want to use node embeddings to differentiate nodes
- If two nodes have highly-overlapped receptive fields, then their embeddings are highly similar
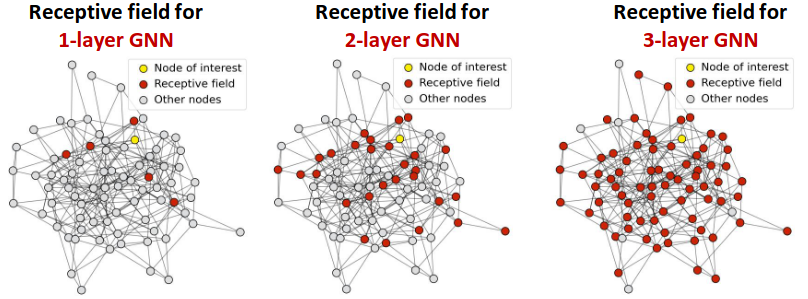 cs224w - lecture 5. slide
cs224w - lecture 5. slide
What do we learn from the over-smoothing problem?
- Be cautious when adding GNN layers
- Step 1: Analyze the necessary receptive field to solve your problem.
- Step 2: Set number of GNN layers to be a bit more than the receptive field we like. Do not set to be unnecessarily large!
How to enhance the expressive power of a GNN, if the number of GNN layers is small?
- We can make aggregation / transformation become a deep neural network!
- Add layers that do not pass messages (A GNN does not necessarily only contain GNN layers)
- Pre-processing layers: Important when encoding node features is necessary.
E.g., when nodes represent images/text - Post-processing layers: Important when reasoning / transformation over node embeddings are needed
E.g., graph classification, knowledge graphs
- Pre-processing layers: Important when encoding node features is necessary.
What if my problem still requires many GNN layers?
- Add skip connections in GNNs
Keys: Node embeddings in earlier GNN layers can sometimes better differentiate nodes
Solution: We can increase the impact of earlier layers on the final node embeddings, by adding shortcuts in GNN
Skip connections create a mixture of models. ( skip connections → possible paths)
We automatically get a mixture of shallow GNNs and deep GNNs
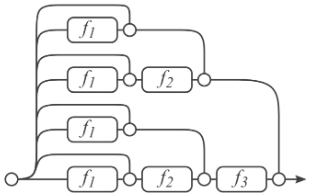
Other options: Directly skip to the last layer
Why need to manipulate graphs?
- Our assumption so far has been: Raw input graph = Computational graph
Reasons for breaking this assumption.
- Feature level:
- The input graph lacks features feature augmentation
- Certain structures are hard to learn by GNN (ex. cycle)
- Structure level:
- The graph is too sparse (Inefficient message passing)
Add virtual nodes / edges- Suppose in a sparse graph, two nodes have shortest path distance of 10.
- After adding the virtual node, all the nodes will have a distance of 2
(Node A – Virtual node – Node B)
Greatly improves message passing in sparse graphs
- The graph is too dense (Message passing is too costly)
Sample neighbors when doing message passing - The graph is too large (Cannot fit the computational graph into a GPU)
Sample subgraphs to compute embeddings
- The graph is too sparse (Inefficient message passing)
- previous Graphs - Embedding
- next Graphs - Aug. and Training