PyTorch
| update: 2023-01-31, update pytorch 2.0
2.x#
PyTorch 2.0 offers the same eager-mode development and user experience, while fundamentally changing and supercharging how PyTorch operates at compiler level under the hood.
Underpinning torch.compile are new technologies – TorchDynamo, AOTAutograd, PrimTorch and TorchInductor.
💡 We don’t modify these open-source models except to add a torch.compile call wrapping them.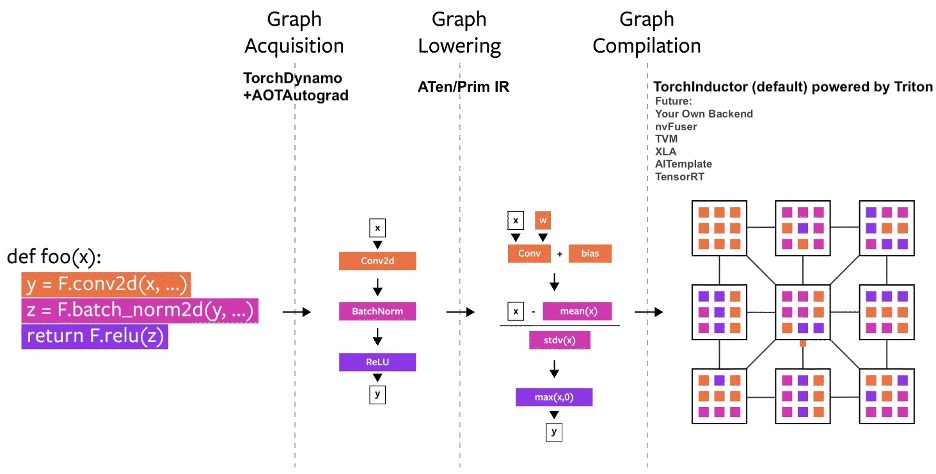
TorchDynamo: Acquiring Graphs reliably and fast
- captures PyTorch programs safely using Python Frame Evaluation Hooks.

An approach that uses a CPython feature introduced in PEP-0523 called the Frame Evaluation API. We took a data-driven approach to validate its effectiveness on Graph Capture.
AOTAutograd: reusing Autograd for ahead-of-time graphs
- engine as a tracing autodiff for generating ahead-of-time backward traces.
AOTAutograd leverages PyTorch’s torch_dispatch extensibility mechanism to trace through our Autograd engine, allowing us to capture the backwards pass “ahead-of-time”. This allows us to accelerate both our forwards and backwards pass using TorchInductor.
PrimTorch: fast codegen using a define-by-run IR
- a set of ~250 essential operators. (2000+ op. -> ~250 op.)
Prim ops with about ~250 operators, which are fairly low-level. These are suited for compilers because they are low-level enough that you need to fuse them back together to get good performance.
TorchInductor: ast codegen using a define-by-run IR
TorchInductor uses a pythonic define-by-run loop level IR to automatically map PyTorch models into generated Triton code on GPUs and C++/OpenMP on CPUs. TorchInductor’s core loop level IR contains only ~50 operators, and it is implemented in Python, making it easily hackable and extensible.
Triton, developed by OpenAI
Triton is a language and compiler for writing highly efficient custom Deep-Learning primitives. The aim of Triton is to provide an open-source environment to write fast code at higher productivity than CUDA, but also with higher flexibility than other existing DSLs.
# API NOT FINAL
# default: optimizes for large models, low compile-time
# and no extra memory usage
torch.compile(model)
# reduce-overhead: optimizes to reduce the framework overhead
# and uses some extra memory. Helps speed up small models
torch.compile(model, mode="reduce-overhead")
# max-autotune: optimizes to produce the fastest model,
# but takes a very long time to compile
torch.compile(model, mode="max-autotune")Reading and updating Attributes#
If attributes change in certain ways, then TorchDynamo knows to recompile automatically as needed.
# optimized_model works similar to model, feel free to access its attributes and modify them
optimized_model.conv1.weight.fill_(0.01)
# this change is reflected in modelHooks (Jan 2023)#
Module and Tensor hooks don’t fully work at the moment, but they will eventually work as we finish development.
Inference and Export#
For model inference, after generating a compiled model using torch.compile, run some warm-up steps before actual model serving. This helps mitigate latency spikes during initial serving.
# API Not Final
exported_model = torch._dynamo.export(model, input)
torch.save(exported_model, "foo.pt")Debugging Issues#
- previous Learn ChatGPT from ChatGPT
- next PyTorch - Optimizer