Spotify's RecSys
Spotify's Recommender System
Inside Spotify’s Recommender System: A Complete Guide to Spotify Recommendation Algorithms by Dmitry Pastukhov, at February 9, 2022
위 글을 정리한 내용입니다.
소개#
2020년대로 접어들면서, AI 기반 추천 시스템의 도움으로 음악 스트리밍 시장이 커지고 있다. 2020년에는 소비자의 62%가 (Spotify 및 YouTube와 같은 플랫폼에서) 음악 검색의 상위 목록에 대해 평가 (좋아요/싫어요) 하였다. 상위 목록만 소비되는 문화는 추천 시스템에 의해 더 건강한 소비 문화로 변경될 것이다. 예를 들어 Spotify에서 발표된 Made to be Found 보고서에 따르면 모든 새로운 아티스트 발견의 1/3 이상이 “Made for You” 추천 세션을 통해 발생합니다.
추천 시스템의 도입으로 단순히 차트 상위 음악들만 소비되는 것이 아니라 청취자의 기호에 따라 더 다양한 음악이 소비되고 있다. 이를 통해 음악가들의 방식도 변경되고 있다.
알고리즘 기반 추천이 음악 산업 중심에 있지만 아직 미지 영역으로 간주되고 있다. 어떻게 음악가들이 추천이 되고 작동이 되는지 명확히 알기 어렵다. 그럼에도 음악 산업은 추천 시스템에 의존하여 새로운 청취자들과 신규 앨범 런칭을 위해 광고비용을 늘리고 있다.
이글은 AI 기반 추천 시스템이 어떻게 음악 산업에 어떤 과정을 통해 영향을 미치는지 주목하려고 한다.
어떻게 Spotify의 음악 추천이 작동할까?#
매우 다양한 방식으로 Spotify의 추천 시스템 엔진은 음악가 (artists)와 소비자 (fans)들을 모두 고려하여 작동하고 있다. Spotify의 긍정적인 측면으로 연구 및 개발 정보를 공개하고 있다. 하지만, 우리는 해당 정보들을 자세하게 소개하려는 것은 아니다. 우리는 사실에 기반하여 쉽게 이야기하려고 한다.
Artificial Intelligence (AI, 인공지능)은 굉장히 넓은 포괄적인 개념이다. Terminator, Skynet을 상상한다면 AI에 해당한다. Machine Learning (ML, 기계 학습)은 AI의 하위 개념으로 세부적인 설계를 통한 것이 아닌 데이터를 통해 패턴을 찾아 특정 목적을 예측하는 학습 방법을 말한다. Deep Learning (DL, 심층 학습)은 ML의 하위 개념으로 ML 모델 요소 중 하나인 Neural Network에 집중하여 Network 구조를 다층 체계화하여 학습하는 방법을 말한다.
Behind the algorithm: 음악과 사용자 이해하기#
AI 추천 시스템의 중심은 사용자 확보, 체류 시간 증가에 집중하고, 궁극적으로는 수익을 발생시키는 것이다. 추천 시스템이 작동 되기 위해서는 무엇이 어떻게 사용자에게 추천되는지 이해가 필요하다. Spotify는 여러개의 독립적인 ML 모델을 통해 음악 정보(item representation)와 사용자 정보(user representation)를 생성한다. 이 과정이 어떻게 이루어지는지 앨범/가수 정보(track/artist representation)를 시작으로 알아본다.
Generating Track Representations: Content-based and Collaborative filtering
Spotify의 접근법은 두가지 핵심 요소로 구성된다.
- Content-based filtering (정보 기반 추천), 앨범 자체에 목적을 두고 정보를 표현한다.
- Collaborative filtering (유사 기반 추천), 사용자를 통해 생성된 데이터간 상관관계에 기반하여 표현한다.
추천 알고리즘은 두가지 접근법을 모두 필요로 한다. 새로운 앨범이나 곡이 등록 되었을 때 설명 정보가 부족하거나 사용자 데이터가 부족하기 때문이다. 해당 문제를 cold start problem이라 한다.
Content-based filtering#
먼저, Content-based filtering 알고리즘에 대해 살펴본다.
Analyzing artist-sourced metadata
Spotify는 신규 등록된 앨범이 있을 경우 알고리즘을 이용해 제작자로부터 제공된 부가정보 (metadata)와 내부 규정된 부가정보를 분석한다. 이상적인 경우 모든 부가정보들이 제공되어 있는 것이다.
다음 정보들이 포함되어 있을 것이다.
- 앨범명, 발매일, 가수명, 참여 가수, 작곡 및 작사가, 소속사 혹은 제작사, 장르, Mood, Music style, Custom Features, etc.
Analyzing raw audio signals
두번째는 음원 분석이다. 여기서 어떤 정보가 분석되어 나오는지는 명확하지 않다. 하지만, 몇가지 추정 가능하다. Spotify API에 따르면 몇가지 음향 특성에 기반하고 있다. 예를 들면 특성
instrumentalness은 해당 곡에 보컬 (목소리)이 얼마나 차지하는지 (예측) 수치화 되어 있다. 해당 곡이 악기 위주의 곡이면1보컬이 많다면0에 가까운 점수로 표현이 된다.원 글
the objective sonic description을특성으로 간단히 번역하였다. 설계된 특성이 좀더 명백한 설명이지만 편의상 간단히 번역하였다.위의 API에 따르면 Spotify는 기존 곡의 부가정보 외에 상위 개념 특성을 생성한다.
Example features of Spotify API:
- Danceability describes how suitable a track is for dancing based on a combination of musical elements including tempo, rhythm stability, beat strength, and overall regularity. A value of 0.0 is least danceable and 1.0 is most danceable.
- Energy is a measure from 0.0 to 1.0 and represents a perceptual measure of intensity and activity. Typically, energetic tracks feel fast, loud, and noisy. For example, death metal has high energy, while a Bach prelude scores low on the scale. Perceptual features contributing to this attribute include dynamic range, perceived loudness, timbre, onset rate, and general entropy.
- Valence: A measure from 0.0 to 1.0 describing the musical positiveness conveyed by a track. Tracks with high valence sound more positive (e.g. happy, cheerful, euphoric), while tracks with low valence sound more negative (e.g. sad, depressed, angry).
위의 예들은 몇가지 특성에 불과하다. 아래 그림처럼 Spotify는 곡 자체를 구조 (음정, 멜로디, 코드, 악기 단위) 분석하여 특성을 만들어낼 것이다. 또한 위의 해당 특성들은 2013년에 공개가 되었으며, 일부에 불과할 것으로 보인다.

Spotify의 분석 알고리즘 연구는 10년이 넘어가고 있다. 지금은 훨씬 더 많은 발전을 이루었을 것이다. 2021년 GraphSAGE에 기반한 Spotify의 연구에 따르면, Audio feature로만 42-dimensional vector를 이용하고 있다고 한다. 위의 설명한 특성들을 포함하여 42개의 특성을 이용하고 있다는 것이다.

from the paper “Multi-Task Learning of Graph-based Inductive Representations of Music Content”
즉, 곡 자체에서 엄청난 양의 정보를 자세하게 분석하여 Spotify 플랫폼에 적용하고 있다는 것이다. 중요한 것은 위의 딥러닝 모델이 42개 특성들을 만들어 내는 것이 아니다. 42개 특성들이 학습 데이터로 들어간다는 것이다. 42개 특성들은 개별적인 ML 모델을 통해 나오거나 다년간 Spotify의 축적된 기술이기 때문에 가능한 것으로 보인다. 여러 특성들 역시 Spotify만의 관점이 아니라 Artist의 관점을 잘 반영하였을 것으로 보인다.
Analyzing text with Natural Language Processing (NLP) models
Content-based filtering의 마지막 요소로 자연어처리 (NLP) 모델이 있다. 자연어처리 모델이 하는 것은 특정 앨범 혹은 가수와 관련된 글들을 분석하여 의미를 추출한다.
해당 모델들이 하는 것은 다음의 예가 있다.
Lyrics analysis: 가사 분석을 통해 곡의 테마나 의미를 얻는다. 또한, 위험성이 있는 단어나 민감한 정보를 포함하는지 확인한다. (지역, 특정인 이름, 브랜드)
TMI: 라디오에서 Pop은 브랜드 언급이 가능하지만, 국내 곡은 브랜드 언급이 불가하다.
Web-crawled data: 블로그나 미디어 매체를 통해 얻는 정보들은 Spotify 내에서 얻을 수 없는 정보들이다. 가수나 곡에 대한 다양한 느낌이나 표현을 얻을 수 있다.
User-generated playlists: 플레이 리스트 제목에 포함된 단어들을 통해 정보를 얻는다. “슬픔”이란 단어를 포함하는 플레이리스트들에 자주 등장하는 곡이라면 해당 곡은 슬픈 무드를 가지고 있을 확률이 크다.
NLP 모델을 통해 사용자들은 곡에서 어떤 느낌을 받는지 음향 분석을 확장할 수 있다.
Spotify의 Content-based 추천 시스템 요소들:
- artist-sourced metadata
- audio analysis
- NLP models
Collaborative Filtering (CF)#
Collaborative Filtering는 많은 추천 시스템에 적용되어 있다.
CF는 곡을 추천할 때 비슷한 취향을 가지는 사용자를 찾아 해당 곡을 추천한다. 알고리즘은 사용자를 찾을 때 사용자의 청취 기록에 기반한다. 만약 사용자 A가 곡 X, Y, Z를 즐겨 듣고, 사용자 B가 X, Y를 즐겨 듣고 Z는 아직 못 들어봤다. 그렇다면 곡 Z를 사용자 B에게 추천한다. 해당 정보들은 아래와 같이 User-Item interaction matrix에 저장되어 있을 것이다.
- Row에 해당하는 정보는 User 한명이 어떤 곡들과 interaction을 가지고 있는지 이고, Column에 해당하는 정보는 특정 곡 하나가 어떤 User들과 interaction 하고 있는지 나타내고 있다. Row (User) 별로 비교하여 동일한 (혹은 비슷한) Row 정보를 가지고 있으면 유사한 취향을 가지고 있다고 할 수 있다.
- 아래의 Matrix를 M이라고 했을 때 를 하게 되면 User-User Interaction matrix가 나오게 된다 해당 element 당 의미하는 것은 사용자와 사용자간의 interaction의 합이다. 해당 값이 높을 수록 사용자간 취향이 비슷하다고 할 수 있다. CF의 방법 중 하나이다.
Spotify는 현재 (2022Q4 기준) 2.05억명의 유로 구독자가 있다. 하나의 Matrix에 모든 정보를 담을 수 없다. Spotify는 효율적으로 Matrix 정보를 관리하기 위해 자체적인 관리 툴 (Annoy)이 있다.
위의 방법이 모든 것을 해결해줄 것 같지만 아니다. 실제는 위의 방법은 정확도, 확장성, 속도, 사용자 및 곡간의 정보 부족 등의 문제를 겪는다. 그래서 Spotify는 소비 기반의 필터링 방법에서 Session 기반의 필터링 방법으로 무게를 두고 있다. 예, “두 곡이 같은 플레이 리스트에 존재하면 유사하다.”
실제로는 많은 사용자가 매우 다양한 범위의 음악을 듣는다. (Spotify는 사용자가 다양한 음악을 듣도록 설계를 하고 있다.) 이말은 많은 사용자가 곡 X와 곡 Y를 듣는다고 해서 두 음악가가 비슷한 것은 아니다. 만약 그렇게 된다면 Metallica (헤비메탈 밴드)와 ABBA (팝/댄스 그룹)을 공유하는 사용자가 많을 것이다. 따라서 플레이 리스트와 재생 목록간의 유사성 확인을 위해 사용자 행동(습관)에 더 자세한 접근이 필요하다.
많은 사용자가 곡 A와 곡 B를 하나의 플레이 리스트에 넣는다면 두 곡은 공통된 특성을 가지고 있을 것이다. 또한 플레이 리스트 제목으로부터 더 나은 통찰력을 얻을 수 있을 것이다.
Spotify의 CF 방식의 추천 시스템이 7억명의 사용자가 생성한 플레이 리스트에 기반하여 학습되고 있다. 플레이 리스트 기반 접근은 단순히 데이터가 많아서가 아니다. 사용자들이 열정, 사랑, 시간을 들여 신중하게 선택하여 생성된 것이다.
플레이 리스트는 사용자가 고려하여 선택된 것들이다. 단순한 이용 기반보다는 조직적일 확률이 크다.
마침내 Content-based filtering과 Collaborative filtering을 모두 살펴 보았다. 한가지 방식에 의존하는 것이 아니라 두가지 방식을 모두 이용하여 곡의 특성을 더욱 풍부하게 만든다. 그럼에도 신규 등록된 곡들은 부족할 수 있다. 곡 자체에 대한 분석과 아티스트의 정보를 이용해 근사될 것이다.
위의 살펴본 것들은 곡 (track) 혹은 가수 (artist) 단계의 데이터를 이용한 상관 관계 기반 추천이다. 우리는 사용자의 정보와 결합해 볼 것이다.
Generating User Taste Profiles#
기본적으로, 추천 엔진은 사용자에 대한 상세 활동을 모니터링하고, 사용자 취향 (User Taste) 분석하는데 이용한다. 예를 들어, 사용자가 “What’s New” 탭을 사용하여 음악들을 빠르게 탐색하고 있다. 초반부만 재생하며, 마음에 드는 음악이면 playlist에 저장, 아니면 건너뛴다. 여기서 Skip이 반드시 부정적 신호라 할 수 없다. 반대로, “Deep Focus” playlist를 background (잠금 상태 혹은 메인 탭이 아닌)에서 skip을 한다면 강한 부정 신호라 볼 수 있다.
일반적으로 사용자 피드백은 두가지 영역으로 나눌 수 있다.
- 직접적 (Explicit, or active) feedback: library 저장, playlist 추가, 공유, skip, 가수 혹은 앨범 클릭, 가수 follow, 지속 청취
- 간접적 (Implicit, or passive) feedback: 청취 시간, 반복적 청취,
Spotify의 추천 시스템은 직접적 피드백에 더 무게를 두고 있다. 음악을 일을 하면서 background에서 듣고 있을 때 (방해 받고 싶지 않은) 청취는 항상 즐거움과 연관된 것은 아니다. 그럼으로 사용자 피드백 데이터는 다음 규약에 따라 처리된다.
- 가장 많이 재생되거나 선호되는 음악과 가수
- 저장된 음악, 앨범 & 팔로우 하는 가수
- 장르, mood, style, 발매일
- 인기성 및 다양성 선호도
- 일시적 행동 패턴
- 인구 통계 및 지리적 정보
그리고 사용자 맞춤형 정보는 소비 상황을 따라 더 나누어진다. 예를 들어 동일 사용자가 일요일 저녁에는 mellow indie-pop을 월요일 아침에는 기운찬 hip-hop을 듣는 다면 Spotify는 아래와 같은 (context-aware) 사용자 정보를 생성한다.
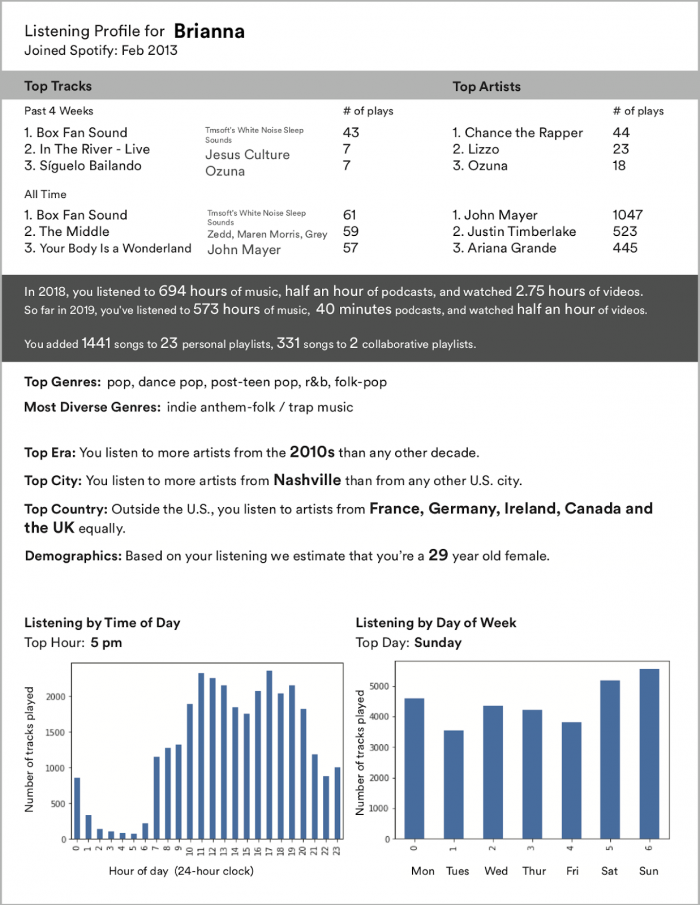
위의 history-based 사용자 정보는 새로운 소비 활동들과 합쳐져 지속적으로 변경된다. historic profile 기반이지만 최근 활동에 더 무게를 둔다. 예를 들어 사용자가 새로운 장르를 듣는다면, 사용자 피드백에 반영되고, 추천 시스템은 해당 곡들과 유사한 음악을 추천하려고 할 것이다. (기존 선호 곡과 매우 다르더라도)
Recommending music: integrating user and track representations#
updated date: 2023-03-19; Adding contents
- previous RecSys Competition - OTTO
- next