InstructGPT
Summary of InstructGPT
Aligning Language Models to Follow Instructions,
January 27, 2022을 읽고 정리한 글입니다.
주관적인 번역이 포함되었습니다.
회색 글자는 개인적인 의견 혹은 정리입니다.
InstructGPT#
GPT-3 자체는 사용자가 특정 명령을 입력하면, 올바른 언어와는 별게로 단순히 학습에 의한 다음 단어만 예측하게 된다.
OpenAI는 언어 모델을 안전하고, 유용하고, 목적성에 맞게 만들기 위해 인간 피드백을 활용한 강화학습(Reinforcement Learning from Human Feedback ,RLHF)을 사용한다. RLHF를 활용하여 목적에 맞게 미세조정한 모델이 InstructGPT이다.
RLHF 과정은 사용자가 특정 명령을 입력하면 모델이 주는 결과들을 인간이 분석하여 적절한 결과를 선택하거나 우선순위를 정한다. 그러면 모델은 인간이 분석한 결과를 가지고 언어 모델을 미세 조정(fine-tune)한다. 그 결과 InstructGPT는 GPT-3 모델 보다 명령을 주었을 때 위험성 있는 단어를 덜 생성하게 되었다.
OpenAI는 단순히 동일 모델에서 비교하는 것 외에 더 작은 모델을 fine-tune하여 기존의 큰 모델과 비교하였다. 그 결과 fine-tune한 작은 모델인 1.3B InstructGPT 모델이 175B GPT-3 모델보다 만족스러웠다.
Results#
아래는 여러 데이터를 통해 검증한 결과이다.
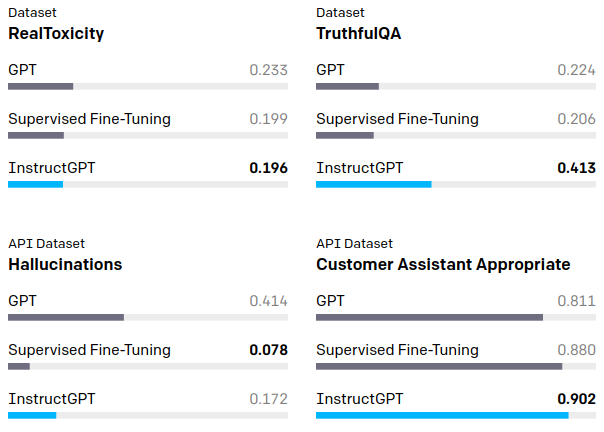
언어 유해성은 기존 모델과 비교하여 개선 되었고, 좀 더 정확한 답변을 하게 되었다. 하지만, InstructGPT의 대답 중 모순이지만 진실된 듯 대답하는 (Hallucinations) 현상은 완전히 개선되지 못하였다.
위의 유해성을 판별하는 요인들은 OpenAI의 Moderation API를 통해 간략히 알 수 있다.
Moderation API에 요청:
curl https://api.openai.com/v1/moderations \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY' \
-d '{
"input": "I want to kill them."
}'Moderation API의 결과:
{
"id": "modr-5MWoLO",
"model": "text-moderation-001",
"results": [
{
"categories": {
"hate": false,
"hate/threatening": true,
"self-harm": false,
"sexual": false,
"sexual/minors": false,
"violence": true,
"violence/graphic": false
},
"category_scores": {
"hate": 0.22714105248451233,
"hate/threatening": 0.4132447838783264,
"self-harm": 0.005232391878962517,
"sexual": 0.01407341007143259,
"sexual/minors": 0.0038522258400917053,
"violence": 0.9223177433013916,
"violence/graphic": 0.036865197122097015
},
"flagged": true
}
]
}Methods#
Labeler는 모델을 목적에 맞게 훈련될 수 있도록 데이터 생성 및 조정, 모델 결과를 검토하는 전문가이다. Labeler에 포함되는 사람들은 목적에 맞는 배경지식을 가진 사람 혹은 깊은 관심을 가지는 예비 사용자가 될 수 있다.
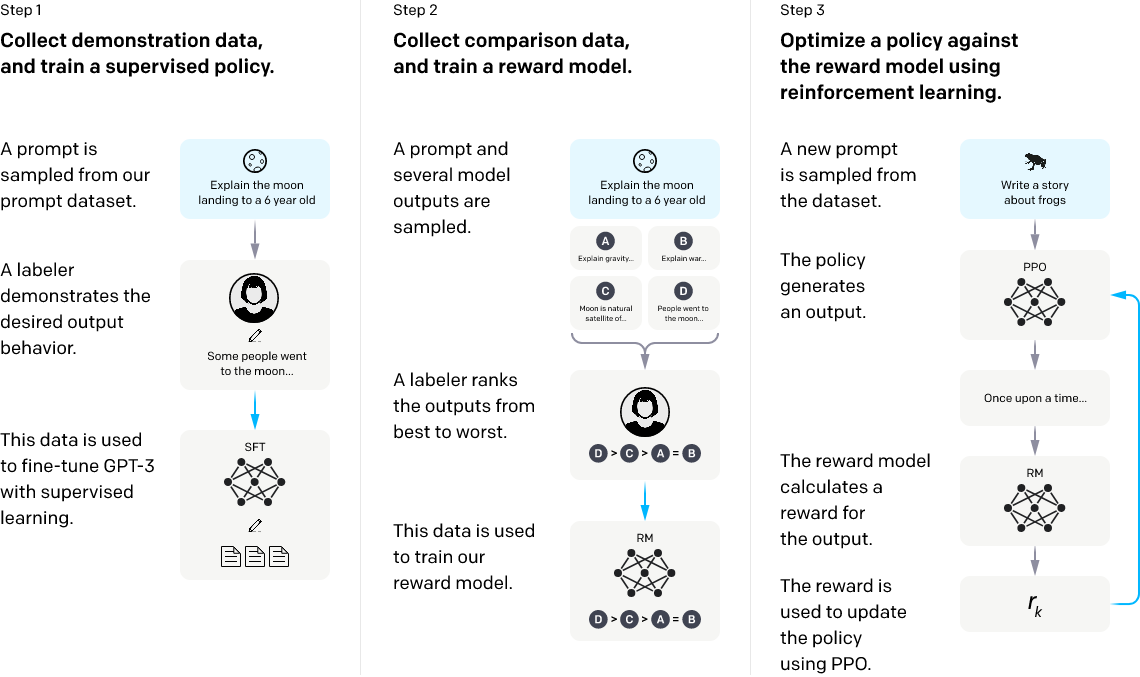
전체적인 과정은 아래와 같다.
- 언어 모델 지도학습 (Supervised Fine-Tune)
- 기존의 입력된 명령들 중 적절한 경우들을 선택하여 테스트 환경을 정의한다.
- Labler는 사전 정의한 명령 기반으로 모델의 output과 자신의 지식을 활용하여 이상적인 결과를 데이터로 생성한다.
- 생성된 데이터를 활용하여 GPT-3 모델을 fine-tune 한다.
- Reward 모델 구성
- 명령어와 해당 명령어의 결과들이 하나의 세트로 구성된 데이터를 준비한다.
- Labeler가 생성된 결과들을 비교하여 순위를 정한다.
- 해당 순위를 바탕으로 reward 모델을 학습한다.
- 강화학습
- 테스트 환경에 사용된 명령들이 아닌 새로운 명령들로 테스트한다.
- PPO 모델을 활용하여, 언어 모델의 행동들을 정의한다.
- Reward 모델을 사용하여 해당 결과를 평가한다.
- 평가 결과를 바탕으로 PPO 모델에 반영하여, 언어 모델의 행동을 조정한다.
강화학습을 사용한 이유는 간단한 평가 방법 하나로 인간의 복잡한 선호를 학습할 수 없기 때문이다. 복잡한 정의를 모두 할 수 없기 때문에 강화학습을 통해 이것을 정의하고자 하였다. 비용과 편의성을 모두 고려한 선택이다.
하지만, 위의 과정 중 지도학습 과정에 크게 비중을 두지 않았다. 이유는 GPT-3의 가능성을 제한할까 걱정이 되었다. 지도학습으로 인해 다른 영역의 기능이 떨어지는 기회비용(Alignment tax)이 발생할 수 있었다. 그래서 기존 학습(pre-train)에 비하여 2% 데이터와 학습 시간을 사용하였다. 이와 더불어, 강화 학습을 이용해 fine-tune 하는 과정에서 정의한 테스트 환경 데이터 외에 기존에 사용된 학습 데이터를 일정 비율 섞어 같이 학습함으로 다른 영역의 기능을 유지하면서 목적에 맞게 학습할 수 있게 되었다.
기존 데이터를 섞어 학습할 때 기존 데이터는 the normal log likelihood maximization를 사용하여 최적화 하였다. 강화 학습에서는 Reward term을 maximization 하는 것이 목적이기 때문에 이와 맞추기 위해 maximization 방식을 그대로 사용한 것으로 보인다. 이와 다른 방법으로 KL Divergence를 사용하여 Reward 방식과 기존 학습 방식을 비슷하게 유지할 수 있지만, 실험 결과 사전 학습 데이터 자체를 likelihood maximization하는 것이 더 효과적이었다.
위의 학습을 통한 모델은 모든 상황에 대하여 보증하기 어렵다. 그래도, InstructGPT 모델 과 Reward 모델 모두 특정 상황에 편향되지 않았다. 특정 영역에서 훈련된 모델을 다른 영역에 테스트 하였을 때 일반화된 성능을 보여주었다. 이것은 단편적일 수 있지만, 더 넓은 영역에서 어떤 영향을 줄지는 연구가 필요하다.
현재 모델이 문화적으로 Labeler와 English 데이터에 편향되어 있을 수 있다. 그리고 사용자 그룹에 따라 결과에 영향을 받는 정도가 다르기 때문에 이 부분 역시 완화해야할 부분이다.
- previous AI Safety
- next RecSys Competition - OTTO